
Ne vous répétez pas… Vraiment ?
Accidentelle ou pas ?
Voici une révélation bouleversante : la duplication de code est une très mauvaise pratique. On n’aurait pas dit, n’est-ce pas ? Je suis sur le cul.
Blague à part, en réalité, j’ai tellement tiré sur l’ambulance dans mes articles que j’ai l’impression d’être un papy qui radote.
Et pourtant, il y a une autre mauvaise pratique liée à la duplication que je n’ai pas du tout abordée, pire, que j’ai malencontreusement encouragé : l’abus de factorisation.
Et c’est maintenant que tu le dis ! Alors que j’ai passé un mois à réécrire toute ma codebase ?!
Hum, hum… et bien en fait… il y a une explication très simple.
Mon article sur la duplication invitait effectivement à factoriser le code au maximum, car la majorité du temps, la duplication est issue d’une erreur humaine : copié-collé, non-connaissance de la codebase… C’est un fléau et doit être éradiqué, rien à ajouter là-dessus.
Mais ce n’est pas sa seule forme, il y a effectivement des cas où il vaut mieux avoir deux modules extrêmement similaires plutôt que groupés en un seul.
C’est ce que l’on appelle la duplication accidentelle : plusieurs modules qui n’ont rien à voir entre eux, hormis une implémentation très similaire.

Par exemple : imaginez que vous écrivez une fonction pour calculer le temps de démarrage de votre smartphone et une autre pour calculer celui de votre micro-ondes.
La tentation de grouper les deux est grande, mais c’est une très mauvaise idée, car elles risquent d’évoluer indépendamment l’une de l’autre.
Si vous les factorisez, alors le jour où vous changez une pièce de votre smartphone, l’algorithme ne fonctionnera plus. Et si vous le modifiez, il remarchera pour le smartphone, mais plus pour le micro-ondes.
C’est ce que l'on appelle une régression : un problème classique lorsque deux modules sont plus couplés que ce qu’ils devraient être.
Et c’est comme ça qu’en voulant bien faire, on fout sa codebase en feu.
Factoriser intelligemment
Du coup, soit on duplique, soit on crée des dépendances trop fortes, fantastiques…
Dans le meilleur des mondes, vous ne devriez faire aucun des deux. Une bonne architecture et une maitrise des patrons de conceptions devraient suffire à vous sortir du pétrin. Mais c’est plus facile à dire qu’à faire.
La solution la plus simple reste de factoriser intelligemment, c’est-à-dire toujours se demander si deux modules ne sont pas accidentellement dupliqués avant de les grouper.
Et on fait comment, Sherlock ?
Ce n’est pas facile, car ça demande une bonne connaissance de la codebase et des exigences, mais il y a un phénomène récurrent.
Plus les modules dupliqués sont proches du domaine métier (bas niveau), plus il y a de chances qu’il s’agisse de duplication accidentelle. Et inversement.
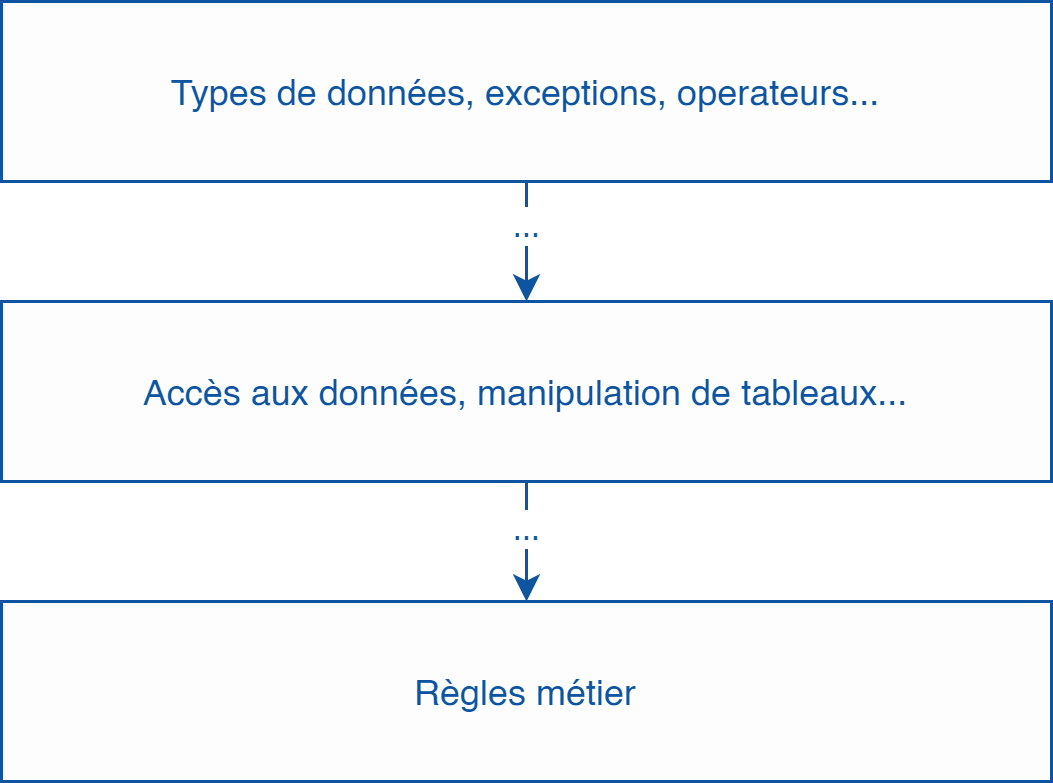
Ça s’explique par le fait qu’une règle métier est, par nature, unique et indépendante du reste. Si une règle métier change, aucune autre ne devrait être impactée.
Le juste milieu
OK, donc plus on est proche du domaine, moins on factorise, j’ai compris.
Heu, non, pas vraiment.
Ce n’est pas parce qu’il y a de la duplication accidentelle qu’il faut faire des gros pâtés de code à l’arrache.
Bien au contraire, car tout module de bas niveau dépend de modules de plus haut niveau qui, eux, ont besoin d’être factorisés.
Voici un exemple : ces deux fonctions prennent un poids et une taille en paramètres, les valident, récupèrent un coefficient dans la base de données, font un calcul, puis retournent le résultat.
Les seules différences sont au niveau du calcul effectué, et du coefficient récupéré (CoefficientB et CoefficientF).
public static double GetF(double weightG, double sizeCm)
{
if(weightG <= 0 || sizeCm <= 0)
throw new Exception("Invalid data");
var weightLbs = weightG / 454;
var sizeInch = sizeCm / 2.54;
var coefficient = db.Query("CoefficientF")
.Where("Weight", ">", weightLbs)
.Where("Size", ">", sizeInch)
.OrderBy("Coef")
.Select("Coef")
.FirstOrDefault<double>();
return (weightLbs * coefficient) / (sizeInch * coefficient);
}
public static double GetB(double weightG, double sizeCm)
{
if(weightG <= 0 || sizeCm <= 0)
throw new Exception("Invalid data");
var weightLbs = weightG / 454;
var sizeInch = sizeCm / 2.54;
var coefficient = db.Query("CoefficientB")
.Where("Weight", ">", weightLbs)
.Where("Size", ">", sizeInch)
.OrderBy("Coef")
.Select("Coef")
.FirstOrDefault<double>();
return (weightLbs / sizeInch) * coefficient;
}Vous remarquerez que ces deux fonctions sont extrêmement similaires, tant dans la structure que dans l’algorithmique. Mais ce sont des règles métier, alors, duplication accidentelle ou pas ?
Oui et non, car même si réunir ces deux fonctions en une seule est une très mauvaise idée (évolution indépendante, tout ça), les étapes individuelles peuvent être factorisées.
public static double GetF(double weightG, double sizeCm)
{
if(!IsWeightValid(weightG) || !IsSizeValid(sizeCm))
throw new Exception("Invalid data");
var weightLbs = ConvertWeight.Convert(weightG, Weight.Grams, Weight.Pounds);
var sizeInch = ConvertSize.Convert(sizeCm, Size.Centimeters, Size.Inches);
var coefficient = db.Query("CoefficientF")
.Where("Weight", ">", weightLbs)
.Where("Size", ">", sizeInch)
.OrderBy("Coef")
.Select("Coef")
.FirstOrDefault<double>();
return CalculateImperialFTangent(weightLbs, sizeInch, coefficient);
}
public static double GetF(double weightG, double sizeCm)
{
if(!IsWeightValid(weightG) || !IsSizeValid(sizeCm))
throw new Exception("Invalid data");
var weightLbs = ConvertWeight.Convert(weightG, Weight.Grams, Weight.Pounds);
var sizeInch = ConvertSize.Convert(sizeCm, Size.Centimeters, Size.Inches);
var coefficient = db.Query("CoefficientB")
.Where("Weight", ">", weightLbs)
.Where("Size", ">", sizeInch)
.OrderBy("Coef")
.Select("Coef")
.FirstOrDefault<double>();
return CalculateImperialBTangent(weightLbs, sizeInch, coefficient);
}J’ai encapsulé chaque étape identique dans sa propre fonction de plus haut niveau, mais pas sans m’assurer qu’il s’agissait bel et bien de vraie duplication.
Pour la validation, la taille et le poids ne pourront jamais être négatifs, peu importe les circonstances, c’est juste impossible, donc la factorisation est valable.
Pour les conversions, c’est pareil. La science ne va pas changer la taille d’un pouce pour le fun.
Pourtant, les calculs sont différents, alors pourquoi les avoir mis dans des fonctions ? Deux choses :
- Pour leur donner un nom sympa.
- Par prévention si jamais on en a besoin autre part, car une fois de plus, la science ne change pas du jour au lendemain.
Et enfin, la partie qui donne des sueurs froides : la requête.
Même structure, même valeur de retour, juste le nom de la table qui change. On est un peu dans une impasse, car :
- Si l’on factorise, il sera plus facile de réparer le code si le schéma de la base change, mais ça casse l’idée d’évolution indépendante.
- Si l’on duplique, pas de risque de régression, mais il faudra modifier le code à plusieurs endroits différents si le schéma de la base change.
Pour le coup, j’ai choisi de dupliquer. Mais cet exemple nous donne deux leçons très importantes :
- Découplez vos composants, de manière à ce que votre programme n’ait pas à connaitre le schéma de la base de données pour fonctionner. Plus de dépendance = plus de problème.
- Connaissez le domaine métier sur le bout des doigts. C’est lui qui donne le contexte autour du programme, et qui, naturellement, vous guidera vers les bonnes décisions (comme pour la validation et la conversion).
Voilà pour cette subtilité concernant la duplication de code. Quelques personnes m’ont fait remarquer que mon précédent article manquait de nuances, donc je me devais de rectifier le tir.
Aussi, si vous avez des critiques concernant certains de mes articles, n’hésitez pas à me les faire parvenir en commentaire. Ça me permet de corriger/améliorer l’article en question, voire d’en faire un complémentaire comme celui-ci 😉
Pensez à partager l’article pour soutenir le blog et propager les bonnes pratiques, et suivez-moi sur Twitter @ITExpertFr où je publie… pas grand-chose ces temps-ci, mais ça va revenir, promis.
Et pour les assoiffés de bonnes pratiques, quelques autres articles pour vous hydrater l’esprit :
- Ne vous répétez pas ! JAMAIS !!
- Comment développer des applications robustes et flexibles ?
- Pourquoi toujours faire UNE SEULE chose ?
Quant à moi, je vous laisse, je repars pour un autre mois de pause parce que je n’en ai pas assez pris. Nan, je rigole, deux semaines, comme d’hab.
À bientôt pour un nouvel article sur le blog des développeurs ultra-efficaces. Tchao !
Afin d'éviter les spams, messages haineux ou insultants envers les autres commentateurs, tous les commentaires sont soumis à modération.