
La programmation fonctionnelle démystifiée : pourquoi et comment ?
Si vous n’avez pas vécu dans une tanière perdue au fin fond du Pérou durant ces 5 dernières années, vous avez sans doute déjà entendu quelqu’un évoquer la programmation fonctionnelle.
Mais si, vous savez, cette nouvelle manière de programmer révolutionnaire qui rend la programmation orientée objets (POO) obsolète et que vous devez absolument maîtriser si vous ne voulez pas vous retrouver à la rue dans 6 mois.

Blague à part, on peut légitimement se demander l’intérêt d’apprendre un nouveau paradigme de programmation en 2020.
Après tout, la POO fonctionne toujours, elle est même plus puissante que jamais et permet de faire tout et n’importe quoi. Et contrairement à ce que j’entends partout, elle est loin d’être morte et elle a encore de belles décennies devant elle, alors quel est l’intérêt ?
Problème
La montée de la programmation fonctionnelle (PF pour les intimes) part d’une observation toute simple : les logiciels sont de plus en plus complexes.
C’est indéniable, il suffit de comparer les programmes d’aujourd’hui et ceux d’il y a encore 15 ou 20 ans pour s’en rendre compte :
- Ils intègrent de plus en plus de patrons de conception : entre les MVC front et back end, les microservices, les gardiens, les décorateurs, les fabriques, les agents, les couches d’accès aux données…
- La quantité d’outils et de frameworks a explosé : il n’est pas rare de voir un programme utiliser un frameworks pour le front-end, un autre pour le back-end, un ou plusieurs outils de tests unitaires, un ORM pour l’accès aux données, et j’en passe.
Cette complexité mène à des programmes qui ont des architectures difficiles à mettre en place. Il faut bien réfléchir à la manière dont les éléments vont s’agencer et comment l’ensemble va mener au comportement voulu, en prenant bien sûr en compte la pérennité et l’évolution de l’application.
C’est sûr que ça change des Hello World!, et ce n’est pas pour rien que certaines personnes en on fait leur métier à plein temps !
Et une fois la bonne grosse architecture mise en place, on pourrait se dire que l’effort s’arrête ici et que tout devient plus simple lorsque l’on commence à développer les fonctionnalités. Mais en réalité, la galère est loin d’être finie.
Car implémenter une belle architecture, c’est top ! Encore faut-il la respecter rigoureusement. Il suffit d’une urgence, d’une erreur, d’une documentation foireuse, ou d’une petite dose de fainéantise pour que les programmeurs commencent à prendre des raccourcis, et bim badaboom, l’architecture bien taillée n’est plus qu’un beau tas de gravats bon pour la benne.
Et là est tout le problème : c’est beaucoup plus facile de ruiner une architecture que de la mettre en place. Ne mentez pas, on l’a tous déjà fait au moins une fois !
Face à cette situation, il y a plusieurs issues possibles.
La première, c’est de maintenir l’architecture en équilibre et s’assurer que les patrons de conceptions sont respectés.
Pour faire ça, on peut utiliser différentes stratégies, comme :
- Une documentation stricte et détaillée.
- Une formation des utilisateurs, en particulier les nouveaux et/ou les juniors.
- Du réusinage de code régulier.
- Des revues de code.
- De la programmation en binôme pour les plus hardcores…
Ça fonctionne, plutôt bien même, mais ça consomme énormément de temps puisqu’il faut faire ça régulièrement sur tout le long du projet.
La deuxième solution est plus simple : se concentrer sur l’objectif et de laisser l’architecture aller là où elle a envie.
Génial ! On progresse vite, et on ne perd pas de temps avec des revues de code qui ne servent a rien. Sauf que dans 6 mois, vous jetez tout à la poubelle et vous recommencez de zéro, parce que la codebase est devenue un gouffre de dette technique totalement impossible à maintenir.
Ou alors, vous vous entêtez, et le projet qui devait vous prendre 6 mois vous en prend 1 an et demi. Et croyez moi, pour avoir travaillé avec des codebase bien merdiques, je n’exagère absolument pas mon propos.
Donc quitte à choisir, optez pour la première solution, ou alors continuez à lire cet article pour découvrir la troisième 🧐
Présentation
Pour résumer, les programmes deviennent de plus en plus complexes et nécessitent des architectures de plus en plus poussées, qui demandent de plus en plus de temps à maintenir.
En réponse à ce problème, la PF vise à ramener la programmation à des concepts plus simples.
C’est tout l’inverse de la POO : là où celle-ci établis des règles et fonctionnalités toujours plus puissantes (décorateurs, gardes, fabriques et j’en passe), la PF pousse à écrire des briques de programmes toujours plus simples et de les empiler pour former le programme final.
Pour faire une analogie, imaginez que vous avez besoin de construire une table.
En utilisant la POO, vous allez avoir une tonne d’outils à votre disposition : scie, perceuse, tournevis, colle, ainsi qu’un tas de planches de bois pour faire la table de vos rêves.
En utilisant la PF, vous allez avoir un kit de pièces qu’il ne vous reste plus qu’à assembler pour construire la table de vos fantasmes.
Par son design, la programmation fonctionnelle propose des avantages très intéressants, car elle permet de faire des programmes :
- Extrêmement modulaires, car ce n’est rien de plus que de l’assemblage.
- Bien plus prédictibles, grâce à des fonctionnalités plus faciles à concevoir, créer, débugger et tester.
- Avec des architectures robustes et difficiles à casser, même en faisant exprès, et ainsi limiter la dette technique.
Voilà pourquoi ce nouveau paradigme fait tant parler de lui.

On va maintenant pouvoir passer aux explications. MAIS ! Avant de commencer, j’aimerais démonter quelques âneries que j’entends régulièrement au sujet de la PF :
La PF redéfinie complètement la manière de créer des programmes !
Non, certes, c’est une manière un peu différente de voir les choses, mais pas besoin de refaire un BAC+5 pour la maîtriser.
Si vous savez déjà bien programmer, il sera facile de vous y mettre. Pour prendre mon cas, j’ai appris les concepts de la PF en un week-end, et les bases de mon premier langage en à peine une semaine. Paye ta révolution.
La PF va tuer la POO !
Non, tout comme la POO n’a pas tué la programmation procédurale (PP). D’ailleurs, la PF n’est pas meilleure que la POO, c’est simplement une manière différente de faire, avec ses avantages et ses inconvénients.
Il faut maîtriser un langage de PF pour en faire !
Non, comme je l’ai dit, la PF réduit la programmation à des concepts très simples et facilement implémentables dans des langages procéduraux et orientés objets. D’ailleurs, la suite de cet article utilisera C#, un langage OO mais qui suffit pour faire de la PF basique.
Voilà, maintenant que les rageux boivent leurs larmes, on peut commencer.
Principe
Commençons par parler de la source d’inspiration de la PF : les mathématiques. Non attendez ne partez pas, promis, ce sera simple !
Vous n’êtes pas sans savoir que beaucoup de notions de programmation se chevauchent avec les mathématiques, à commencer par les fonctions elles-mêmes.
Et oui, le fameux f(x) qui nous aura bien fait chier durant notre scolarité, le principe est quasiment le même au final : une fonction prend une valeur d’entrée (paramètre), passe dans une équation (traitements) et sort un résultat (valeur de retour).
f(x) = x²public static int Pow2(int x)
{
return x * x;
}La différence, c’est qu’en maths, les fonctions ne vont pas aller modifier des propriétés, écrire dans une base de données ou envoyer des signaux à un pool d’agents. Elles ne font que des opérations élémentaires.
Et bien dans un environnement fonctionnel, c’est la même chose ! Les fonctions ne font que des opérations qui retournent un résultat. On dit qu’elles font des traitements sans effet secondaire.
Concrètement, ça veut dire pas de propriétés, pas de BDD, pas de fichiers et pas d’événements. Les seuls éléments extérieurs qui jouent un rôle dans le traitement des fonctions, ce sont les paramètres, et donc des données que l’on maîtrise totalement.
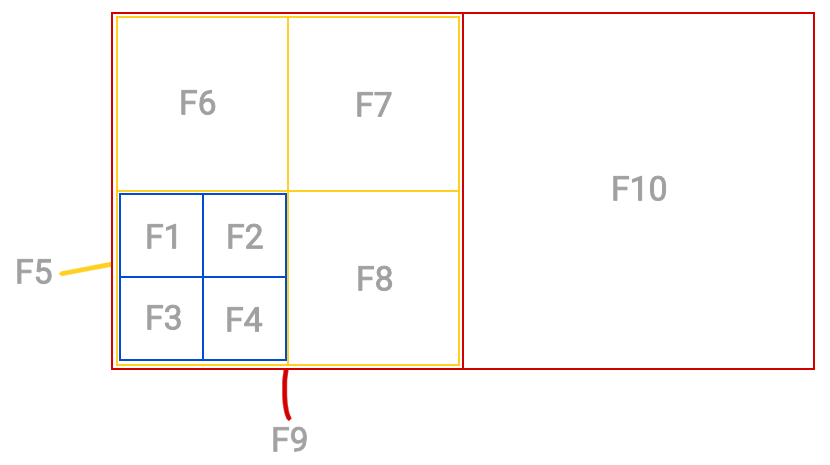
Cette absence d’effets secondaires permet de rendre les fonctions prédictibles, car comme en math, on peut les faire de tête, mais aussi testables, et surtout, ridiculement simples.
Et en PF, on pousse le délire très très loin. Un principe que l’on retrouve fréquemment est l’immutabilité : on ne modifie jamais les variables, on en fait des copies à chaque fois, comme avec des constantes.
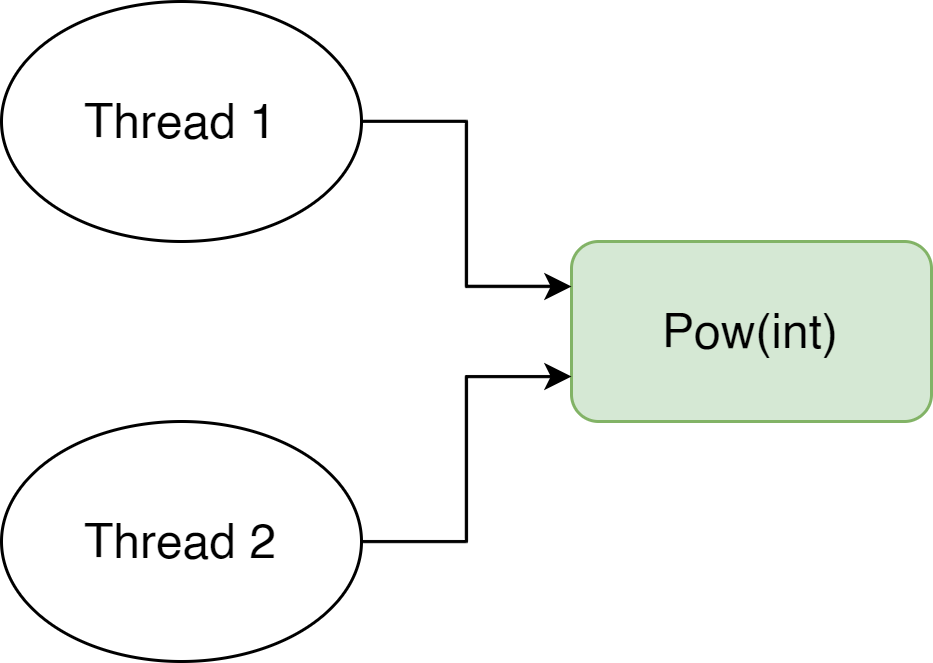
Ces deux éléments sont ce qui rend la PF incroyablement efficace avec les threads. Je pense que l’on connaît tous la galère lorsque deux threads viennent modifier la même donnée en même temps dans une base.
Et bien dans un environnement fonctionnel, grâce à l’immutabilité et l’absence d’effets secondaires, ce genre de situation n’arrive jamais. C’est purement et simplement impossible par principe.
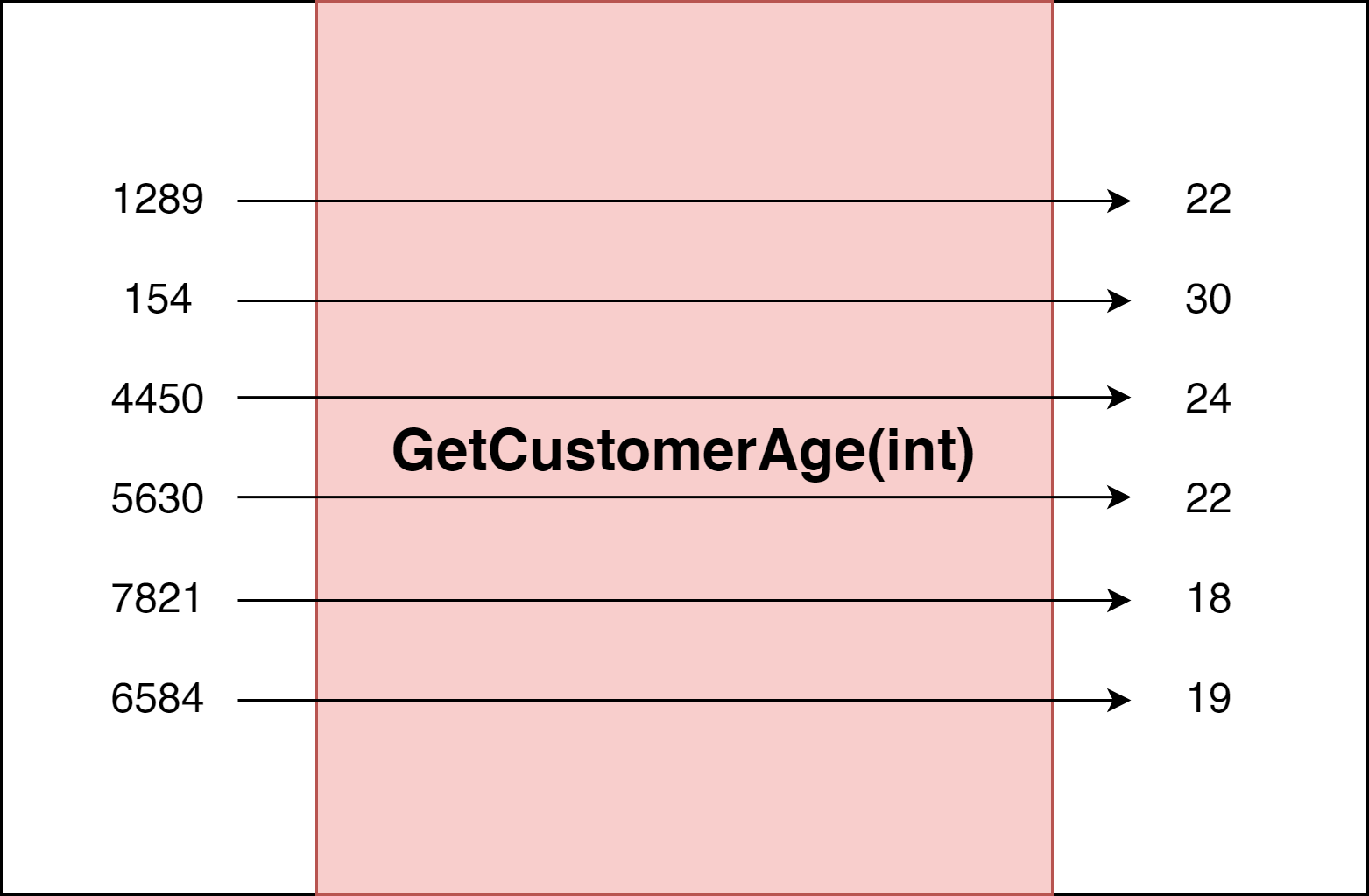
Ok, c’est cool, mais il reste un tout petit souci, mais vraiment un petit détail : à quoi ça sert un programme qui ne fait rien à part retourner des valeurs ? Touché.
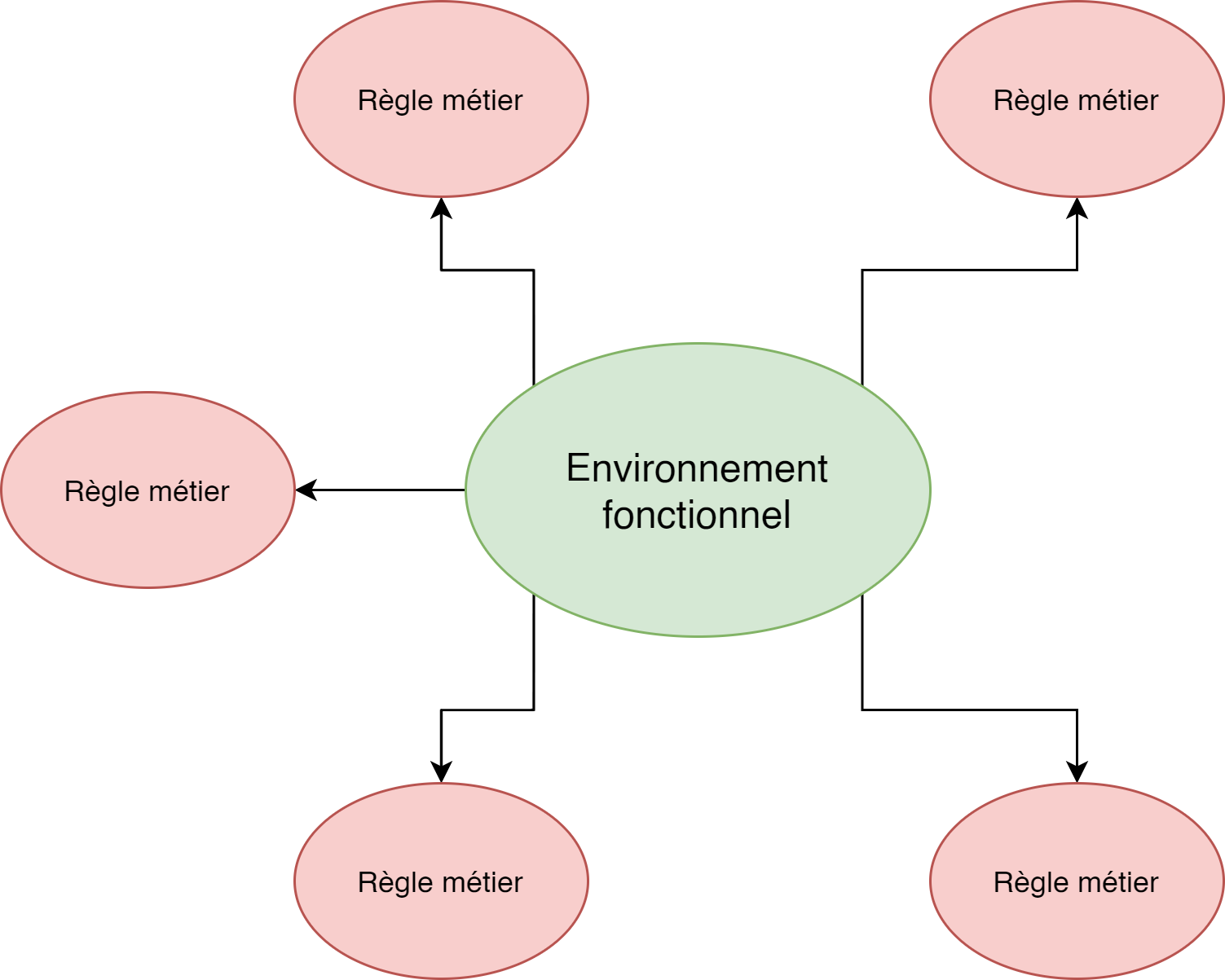
Oui, en réalité, je vous ai un peu menti, car en PF, on fait toujours la distinction entre deux choses très importantes :
- L’environnement fonctionnel : le jardin d’Eden, où effets secondaires et mutations ne sont que les lointains souvenirs.
- Les règles métiers : le shéol, où l’on va venir modifier notre interface graphique et martyriser cette pauvre base de données qui n’a rien demandé.
Et le point culminant de la PF, c’est quand les règles métiers ne font plus que deux choses :
- Des effets secondaires (base de données, requêtes HTTP, écriture dans un fichier…)
- Appeler des fonctions de l’environnement fonctionnel.
Avec ça, on se retrouve d’un côté avec des règles métiers bien moins complexes qu’en POO, et de l’autre, un environnement fonctionnel prédictible et testable, ainsi une architecture ridiculement simple et flexible qui ne prend pas la poussière au bout de 6 mois. La crème de la crème 👌
Programmation
Ça, c’était pour la théorie, maintenant, le fun peut commencer.
Pour les exemples suivants, j’utiliserais le langage C#, parce que c’est un langage que j’aime bien et qui est facile à comprendre.
J’aurais pu utiliser un vrai langage de PF, mais je trouve leur syntaxe assez déroutante pour quelqu’un avec un background POO (où PP), et je pense qu’il est plus pédagogique de présenter le principe avec un langage populaire.
Mais ne vous inquiétez pas, dans un prochain article, on parlera d’un vrai langage de PF ainsi que tous les avantages qui vont avec !
Et pour les amoureux de beaux dessins, j’ai fait un résumé de toutes les notions de cet article en une image dans le bonus de ce post.
Types
En PF comme dans tous les langages, on va retrouver un ensemble de types de base assez classiques : entiers, chaînes de caractères, décimaux, tableaux, listes… Mais bien sûr, s’il n’y avait que ça, on se ferait vite chier.
Pour ajouter de la complexité, on va venir assembler ces types entre eux pour en faire des nouveaux qui représentent des choses plus concrètes, exactement comme pour les structures en C. Pas compliqué n’est-ce pas ?
public record Water
{
public float Quantity { get; init; }
public string Brand { get; init; }
}À noter que contrairement à des classes, les types n’ont pas de comportements (pas de méthodes). Ce ne sont que des données.
Fonctions pures
Enfin des fonctions, ce n’est pas trop tôt !
Comme dit plus haut, elles sont inspirées du modèle mathématique, donc aucune mutation, aucun effet secondaire, et aucune influence extérieure hormis les paramètres.
C’est ce que l’on appelle des fonctions pures. La notion est simple, mais on peut vite se faire piéger. Voici un contre-exemple :
public static TimeSpan TimeElapsed(DateTime originalDate)
{
return DateTime.Now - originalDate;
}Et oui, ici, la fonction n’est pas pure puisqu’elle utilise l’horloge interne pour calculer son résultat, qui est une source extérieure non passée en paramètre.
Ça veut dire qu’avec les mêmes paramètres, on va obtenir un résultat différent sur deux appels, ce qui rend la fonction impossible à tester unitairement de manière systématique. Ce n’est pas bon du tout.
Si on veut faire la même fonction, mais pure, voici à quoi ça ressemblerait.
public static TimeSpan TimeElapsed(DateTime oldDate, DateTime newDate)
{
return newDate - oldDate;
}Composition
Faire ses types et ses fonctions dans son coin, c’est bien marrant, mais ça serait bien de faire communiquer le tout. Et bien pour faire ça, on va utiliser un concept de PF que l’on appelle (roulement de tambour)… La composition ! Avouez, vous n’auriez pas deviné.
Le principe est que l’on va venir assembler nos briques (types et fonctions pures) pour faire de plus grosses briques, que l’on va assembler pour faire d’encore plus grosses briques, que l’on va assembler pour faire un mur : le programme final.
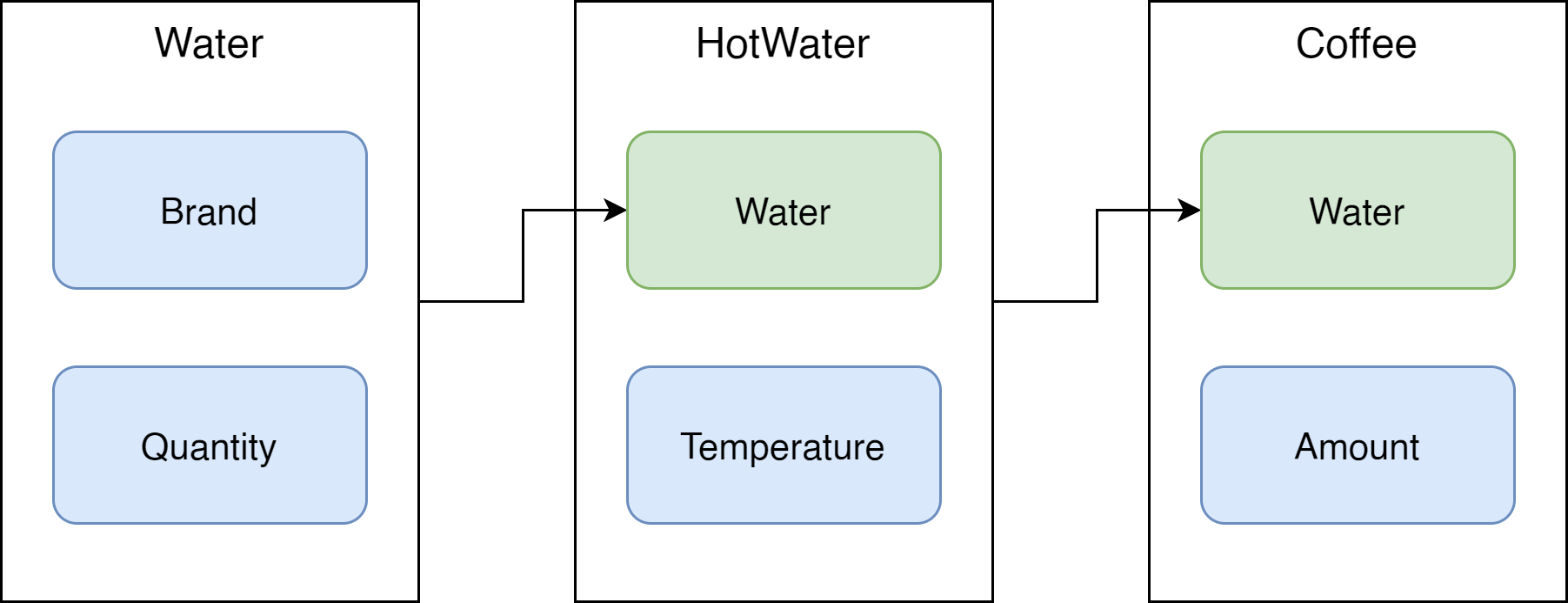
Déjà, on va avoir des types qui contiennent d’autres types. Par exemple :
public record Water
{
public float Quantity { get; init; }
public string Brand { get; init; }
}
public record HotWater
{
public float Temperature { get; init; }
public Water Water { get; init; }
}
public record Coffee
{
public float Amount { get; init; }
public HotWater Water { get; init; }
}
Et les fonctions vont appeler ces types, faire leurs calculs, puis retourner d’autres types (ou les mêmes) qui seront ensuite utilisés dans d’autres fonctions, etc.
public static Water BuyWater(float quantity, string brand)
{
return new Water() { Quantity = quantity, Brand = brand };
}
public static HotWater BoilWater(this Water water, float temperature)
{
return new HotWater() { Water = water, Temperature = temperature };
}
public static Types.Coffee BrewCoffee(this HotWater water, float coffeeAmount)
{
return new Types.Coffee() { Water = water, Amount = coffeeAmount };
}
Bien sûr, il est aussi possible de composer des fonctions entre elles en faisant des fonctions plus complexes qui viendront appeler un ensemble de fonctions plus simples, et qui seront elles même appelées dans des fonctions plus complexes.
public static Types.Coffee MakeCoffee(float quantity, string brand, float temperature, float coffeeAmount)
{
return BuyWater(quantity, brand)
.BoilWater(temperature)
.BrewCoffee(coffeeAmount);
}
Pas mal, mais il y a encore plus balèze : passer des fonctions en paramètre d’une autre fonction. Ça parait complètement absurde, mais la puissance du truc est colossale. Voici un exemple tout simple, mais qui m’a converti plus rapidement qu’un bon blabla d’homme politique :
public static int Add(List<int> list, Func<int, int> action, int initialValue = 0)
{
// Exceptionnellement, j'utilise une variable mutable pour cette fonction.
// Malgré le fait que ce ne soit pas une bonne pratique, ce n'est pas interdit tant que celle-ci ne provoque pas d'effet secondaire.
int res = initialValue;
foreach(int item in list)
{
res += action(item);
}
return res;
}var list = new List<int>() { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
var result = Add(list, x => x * x); // 285Vous comprenez maintenant quand je dis que la PF n’est que de l’assemblage : on va créer plein de petites pièces (types et fonctions) que l’on va coller entre elles pour former notre programme.
C’est ce qui rend la PF très :
- Simple : uniquement 2 notions qui entrent en jeu (types et fonctions), contrairement à la POO où il y en a des dizaines.
- Modulaire : quoi qu’on fasse, on peut toujours ajouter et connecter des pièces à notre puzzle. On est quasiment jamais bloqué.
D’ailleurs, même quand vous partez d’un programme vide, vous faites déjà de l’assemblage, étant donné que vous utilisez des types (int, float, string…) et des fonctions préfaites : les opérateurs.
Connexion au système mutable
Essentiellement, tout ce qu’on a fait jusqu’ici, ce n’est que préparer notre programme pour le vrai défi : les règles métier. Et oui, à un moment ou un autre, il faudra bien y toucher à cette base de données.
Toute cette partie se fait en dehors de l’architecture fonctionnelle, dans ce que l’on appelle des fonctions impures, où toutes les atrocités sont permises.
La seule chose à retenir, c’est qu’une fonction pure ne peut pas appeler une fonction impure. Jamais. Si elle le fait, elle devient impure par définition, car son résultat n’est plus prédictible.
En d’autres mots, une fois arrivé à cette étape, le travail de la PF est terminé, et on repart sur un modèle plus traditionnel : procédural, voir orienté objets.
public static void RecordCoffeeConsumption(float dose)
{
float coffeeAmount = dose * 50;
float waterAmount = dose * 0.2f;
// Code venant de l'architecture fonctionnelle
Coffee coffee = MakeCoffee(waterAmount, "Evian", 70, coffeeAmount);
// Effet secondaire : Base de donnée
Insert_Coffees(coffee.Water.Water.Quantity, coffee.Amount, DateTime.Now);
// Effet secondaire : Action sur l'interface utilisateur
ShowMessage(coffeeAmount + " grammes de café consommé");
// Effet secondaire : Journalisation
Console.WriteLine(coffeeAmount);
}Et c’est à cette étape que l’on se rend compte d’un truc : tant que l’on est dans l’architecture fonctionnelle pure, notre programme est sûr.
Il peut-être mal codé, lent, mal optimisé, ne pas respecter les bonnes pratiques, etc. Mais ce qui est certains, c’est que grâce à son absence d’effets secondaires et de mutabilité, il ne met pas en danger le système.
Ainsi, vous avez tout intérêt à avoir un maximum de fonctions se trouvent dans l’architecture fonctionnelle et que celles-ci soient bien testées, afin de garder uniquement la partie la plus croustillante pour les fonctions impures.
Si vous appliquez rigoureusement les principes de cet article (c’est encore plus simple avec un langage fonctionnel) alors nul doute que vous aurez un programme de qualité, maintenable et évolutif, peu importe sa complexité. C’est ça, la vraie force de la programmation fonctionnelle.
Et voilà ! Avec tout ça, vous deviez être en mesure de comprendre l’intérêt (et l’engouement) autour de la programmation fonctionnelle, et même de faire vos premiers programmes.
Si vous avez besoin de faire apprendre la PF à votre grand-mère en 5m, j’ai mis un bon gros schéma récapitulant toutes les notions de cet article dans le bonus. J’y ai mis aussi une paire de liens bien sympathiques si vous voulez approfondir vos connaissances, allez y, c’est de la bonne.
Et si vous voulez plus de précisions sur certains points que vous avez mal saisi, ou des choses que j’ai loupé, laissez-moi un commentaire juste en dessous, et j’y répondrais avec plaisir !
Pour terminer, je tiens tout de même à relativiser un peu : contrairement à ce que disent les intégristes, la POO reste du très bon cru, et il est tout à fait possible de faire des architectures maintenables sur le très long terme en POO, tout comme il est possible de se rétamer complètement en PF.
Encore une fois, pas de bon ou de mauvais, uniquement des manières différentes de faire, avec leurs avantages et leurs inconvénients.
Sur ceux, je vous laisse, il faut que je me rende à Argenta pour aller battre Pierre. Je vous donne rendez-vous la semaine prochaine pour un nouvel article sur le blog du développeur ultra-efficace !
Accéder au bonus : La programmation fonctionnelle en une image.
Afin d'éviter les spams, messages haineux ou insultants envers les autres commentateurs, tous les commentaires sont soumis à modération.