L'architecture 3 tiers en images.
Pour ce bonus, je vous ai concocté un ensemble de schémas qui compilent tout ce qu’il y a à savoir sur l’architecture 3 tiers, pour débuter dans de bonnes conditions, ou simplement pour vous rafraîchir la mémoire.
Il ne s’agit pas d’un article exhaustif, le web étant tellement complexe qu’il saurait audacieux de dire que je connais ne serait-ce que la majorité de ses subtilités.
Mais ça suffit amplement pour commencer, le reste viendra avec le temps !
Vue d’ensemble
Les 8 étapes clés de l’architecture 3 tiers :
- L’identification du serveur web par le client.
- L’envoi de sa requête HTTP au serveur web.
- Le traitement de la requête par le serveur web.
- La requête du serveur web vers la base de données afin de récupérer les données nécessaires pour la construction de la page.
- La sélection des données par le moteur de la base.
- L’envoi des données au serveur web par la base.
- La construction de la page par le serveur web.
- L’envoi du résultat dans une réponse HTTP au client.

URL
L’URL (Uniform Ressource Locator) est un moyen normalisé d’identifier la ressource que demande un client. Elle se compose toujours de la même manière, en 3 parties :
- Le protocole de communication : le moyen de contacter le serveur.
- Le nom de l’hôte : pour localiser le serveur web qui possède la ressource.
- L’adresse de la ressource sur le serveur : le reste de l’URL.


HTTP
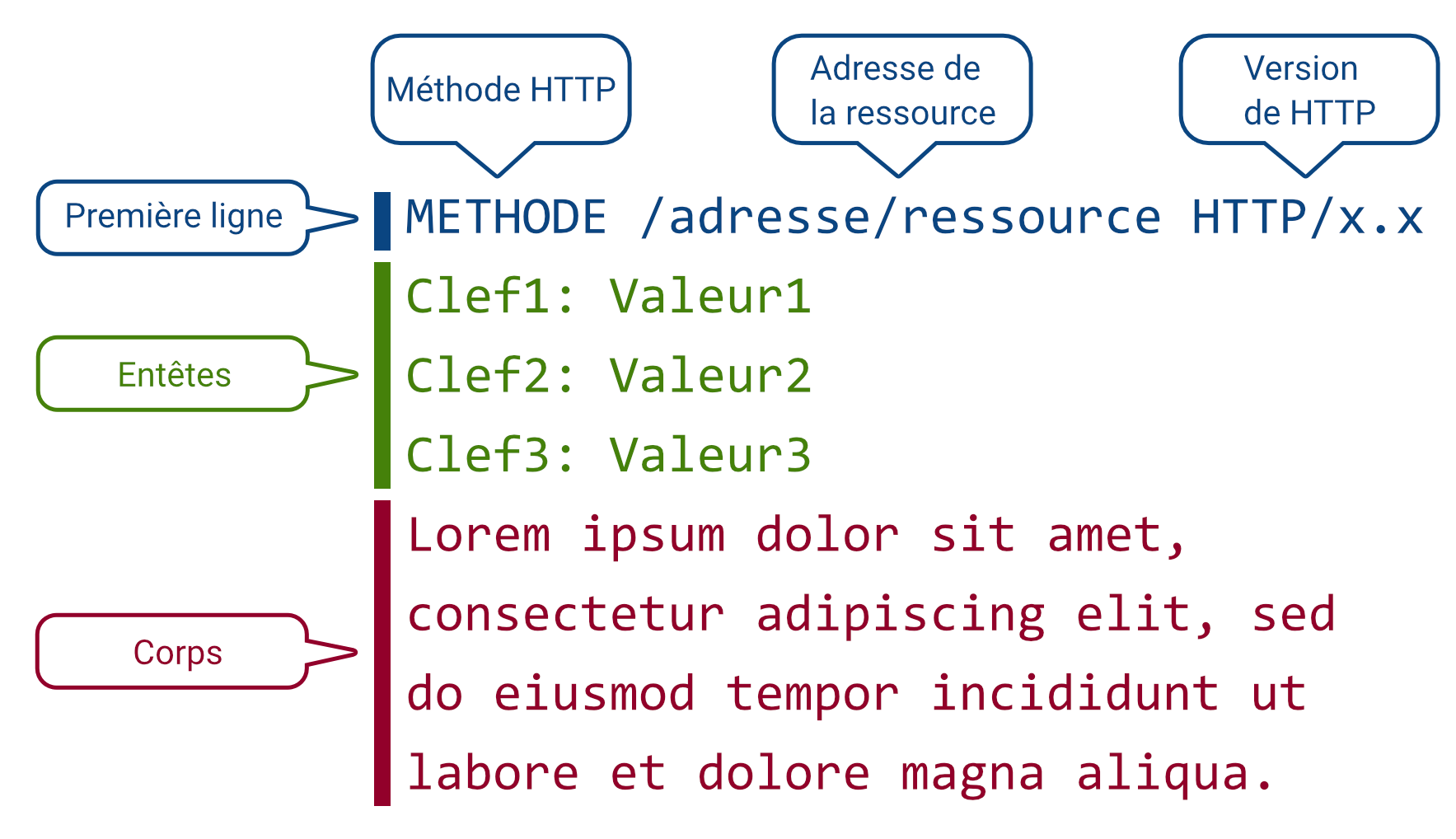
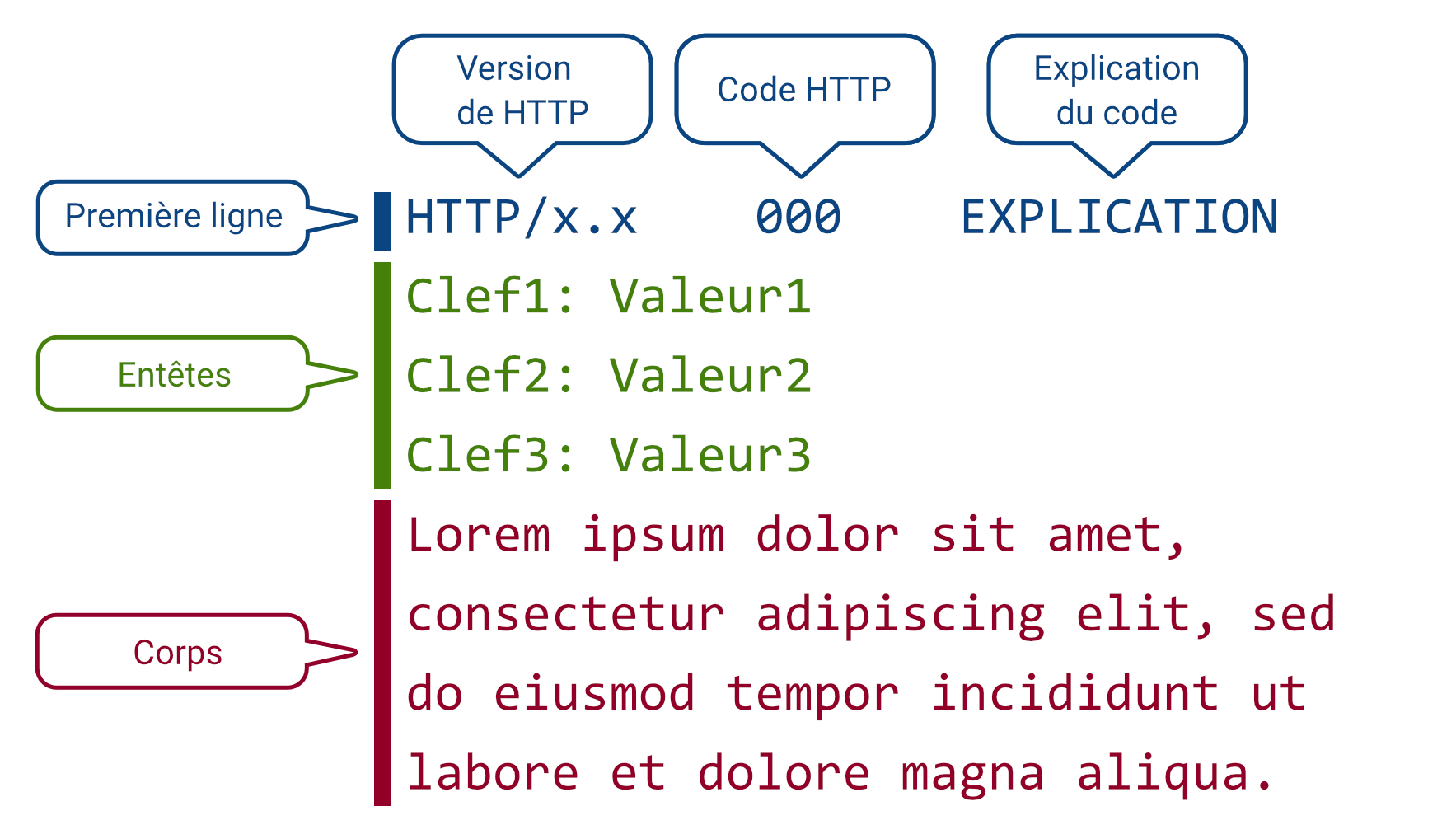
HTTP (HyperText Transfert Protocol) permet au client de demander une ressource auprès d’un serveur web, et au serveur web de lui répondre. Les requêtes/réponses HTTP sont toutes composées de la même manière :
- La première ligne (la seule obligatoire).
- Pour une requête, elle contient l’adresse ressource à récupérer (URL).
- Pour une réponse, elle contient le code de statut.
- Les entêtes, pour configurer le comportement du serveur web.
- Le corps, pour envoyer des données au serveur web.


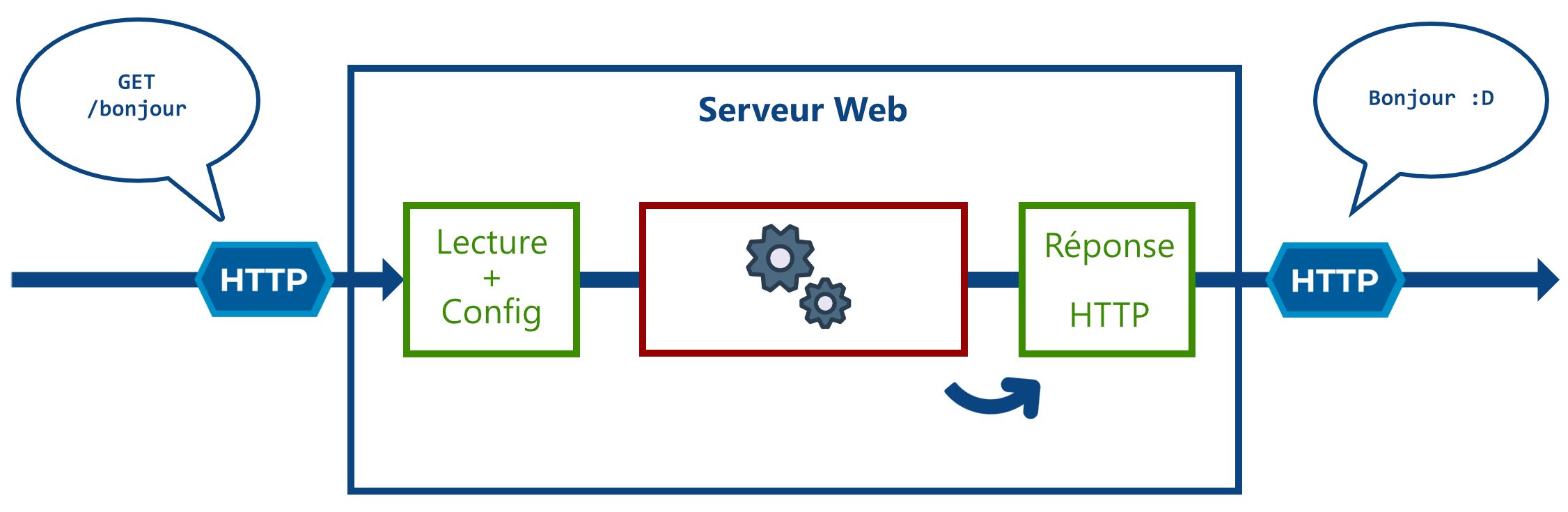
Communication par HTTP
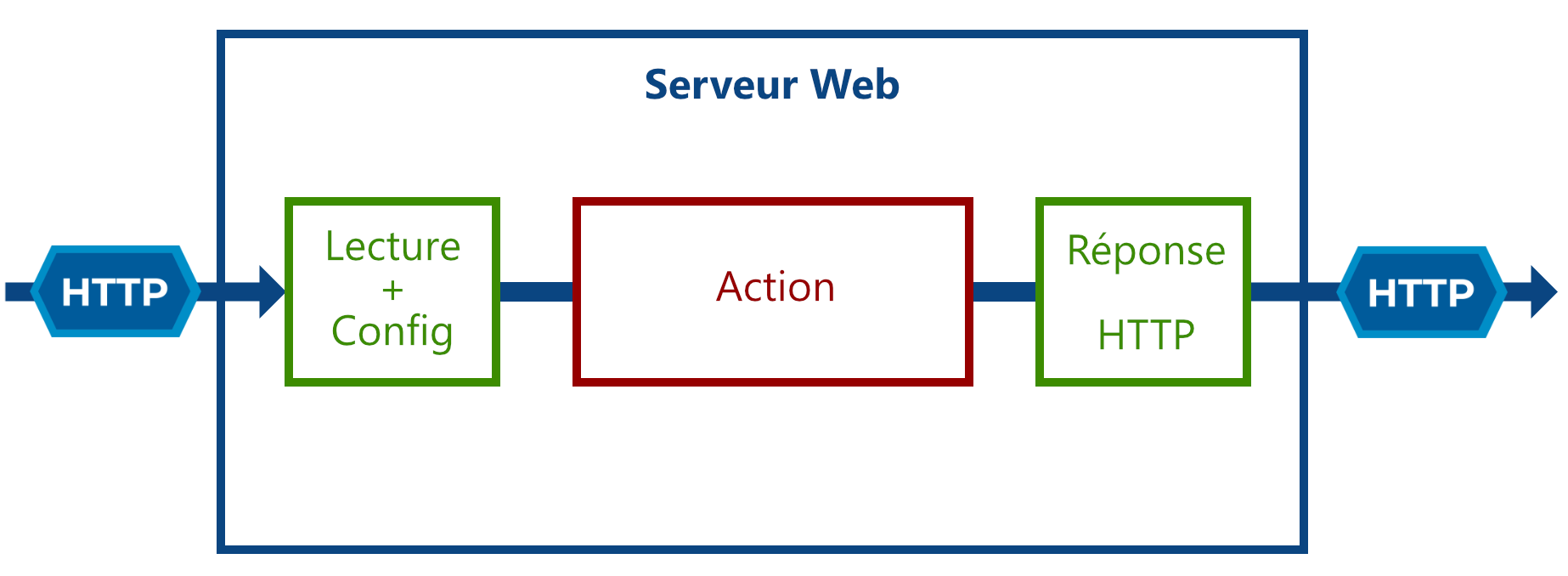
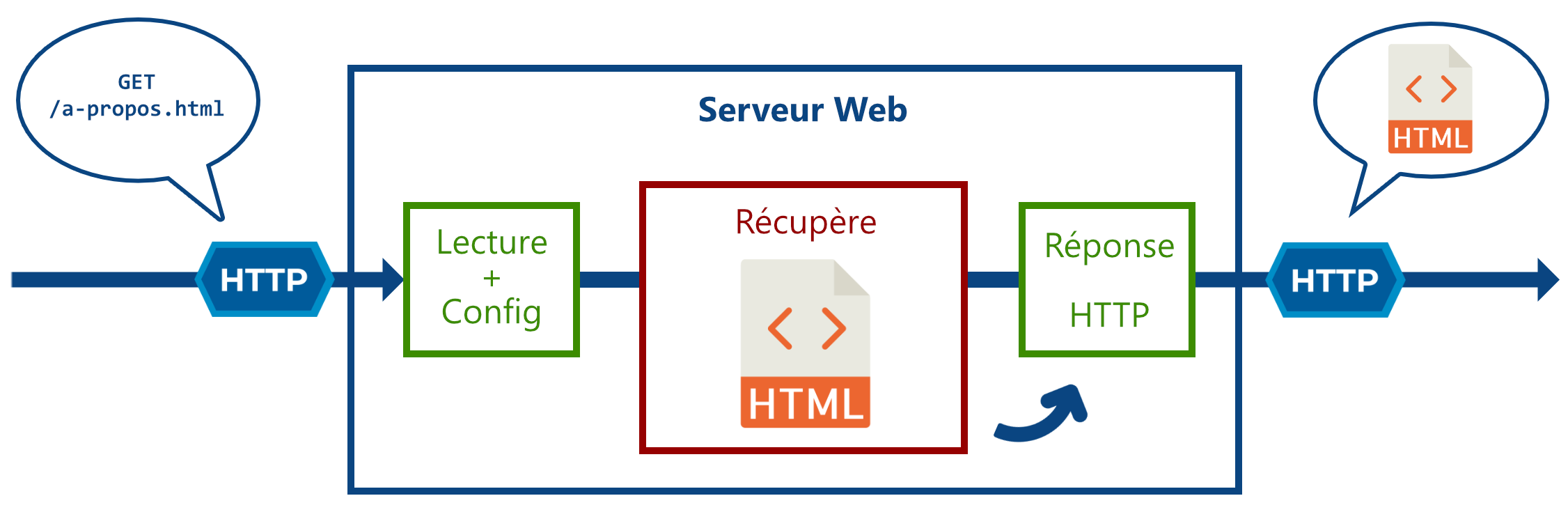
C’est grâce à ce protocole que vous pouvez récupérer tout type de ressource sur le web, tel que :
- Des nombres et du texte.
- Des images/audios/vidéos.
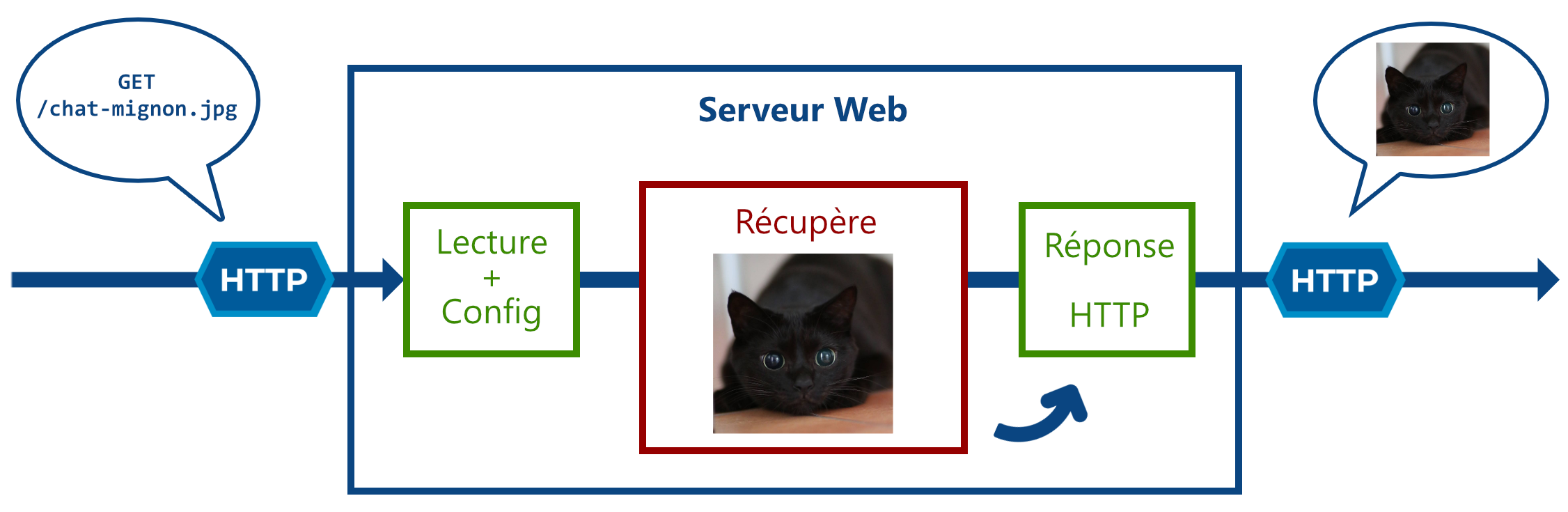
- Des pages HTML.
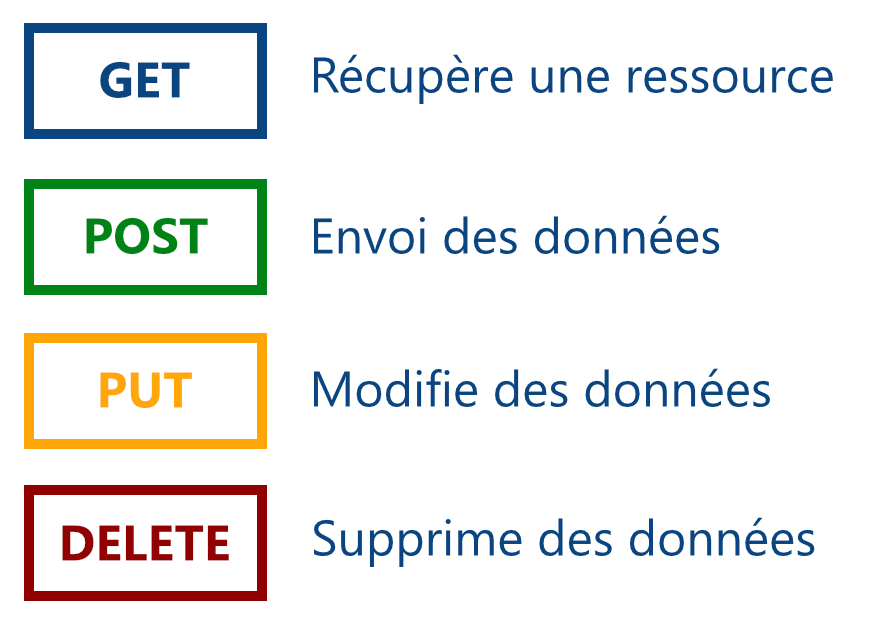
Méthodes HTTP
Elles prennent la forme d’un verbe et permettent de communiquer de différentes manière via HTTP. Vous pouvez toutes les retrouver en suivant ce lien.
Pages web dynamiques
Le grand intérêt de la programmation web back-end est de pouvoir faire des pages web dynamiques, c’est-à-dire construite sur-mesure en fonction de la requête du client.
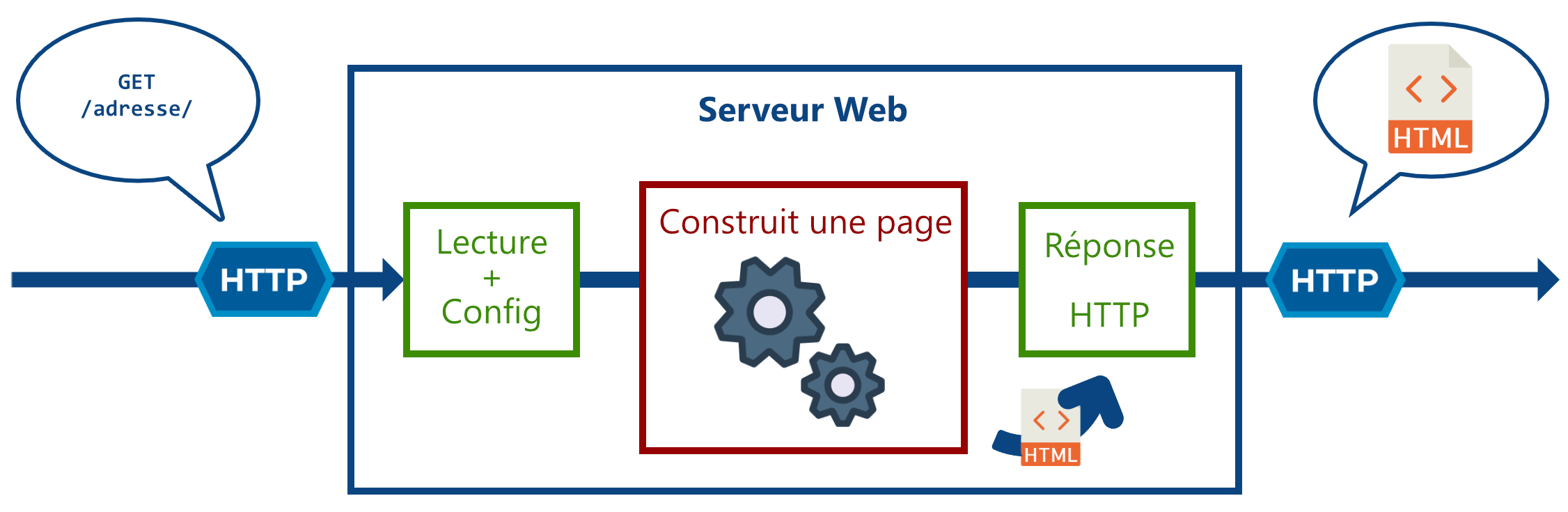
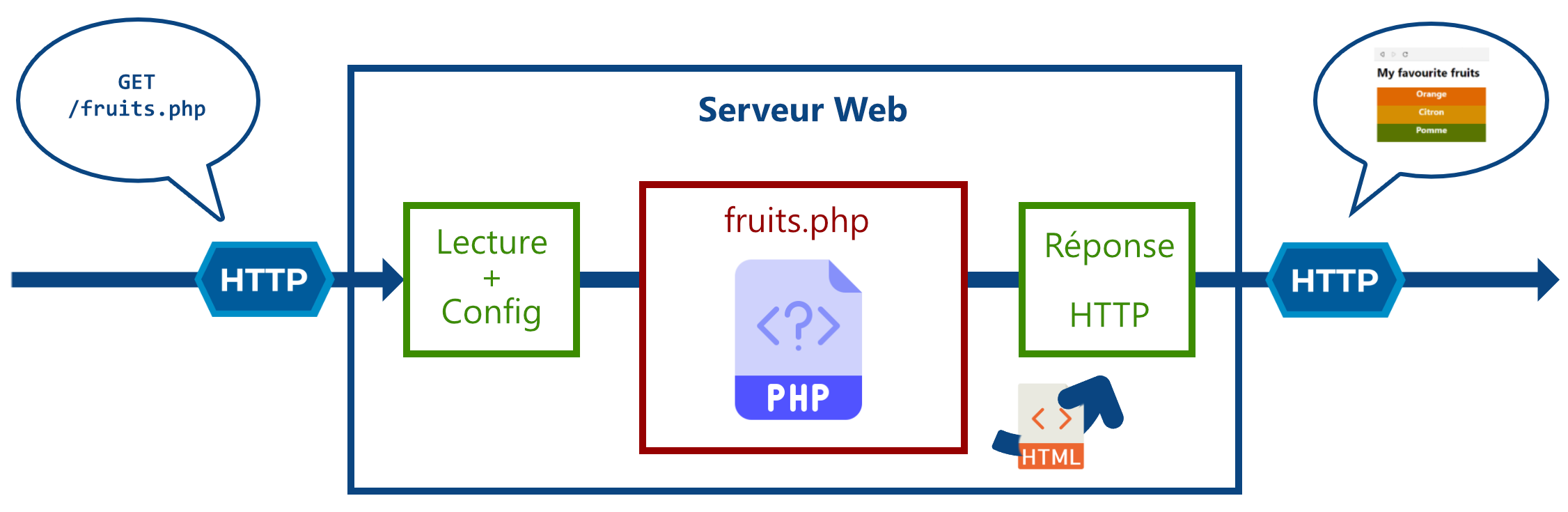
Pour cela, en plus de la localisation de la ressource, le client va envoyer des arguments pour spécifier sa demande.
Ces arguments peuvent être envoyés sous plusieurs formes, en voici 3 :
- Via l’adresse la ressource.
GET /personne/Jean-Pierre/Papin HTTP/1.1
- Via une QueryString.
GET /personne?prenom=Jean-Pierre&nom=Papin HTTP/1.1
- Via le corps de la requête HTTP.
POST /personne
{
"nom":"Jean-Pierre",
"prenom":"Papin"
}
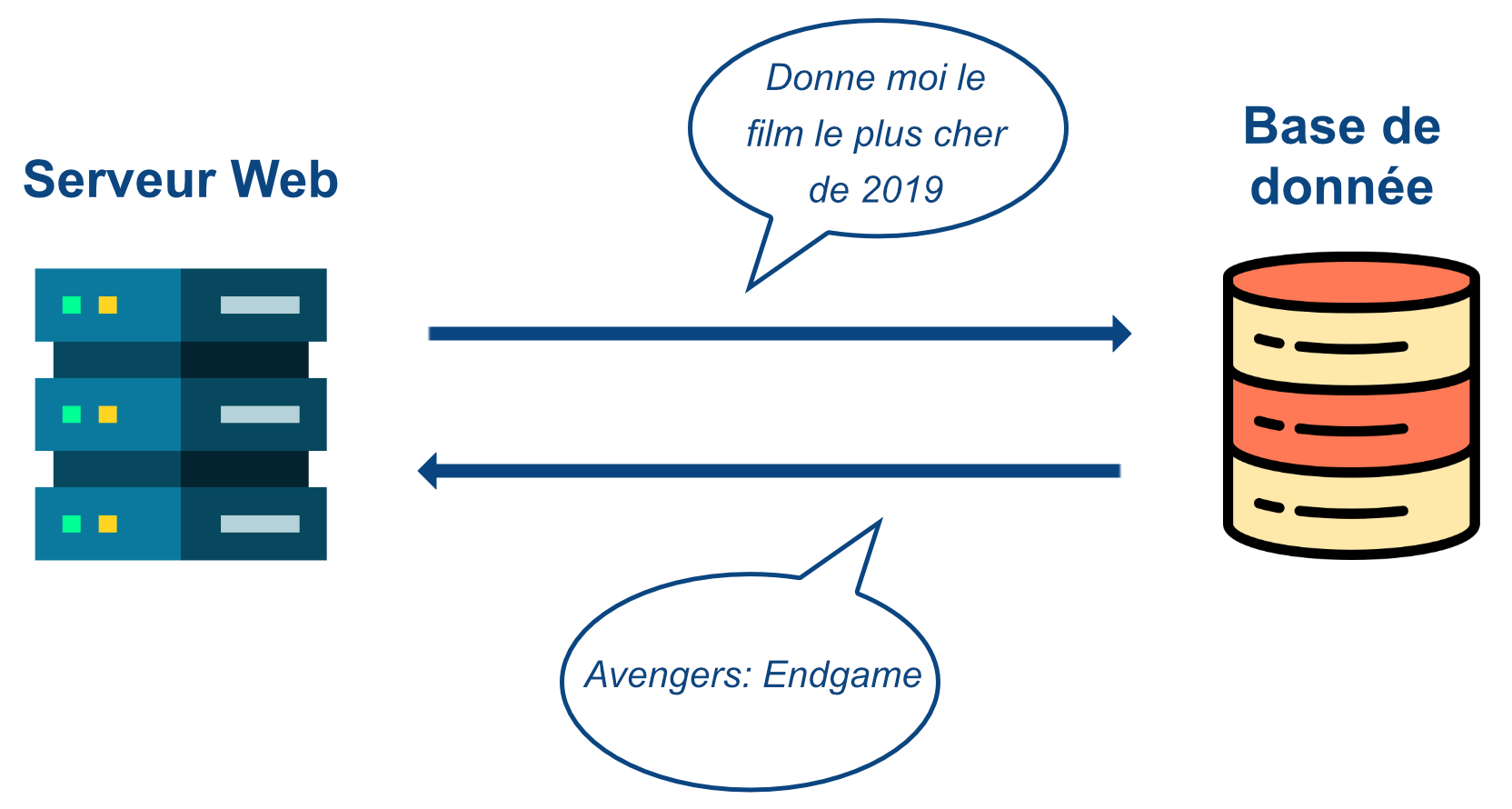
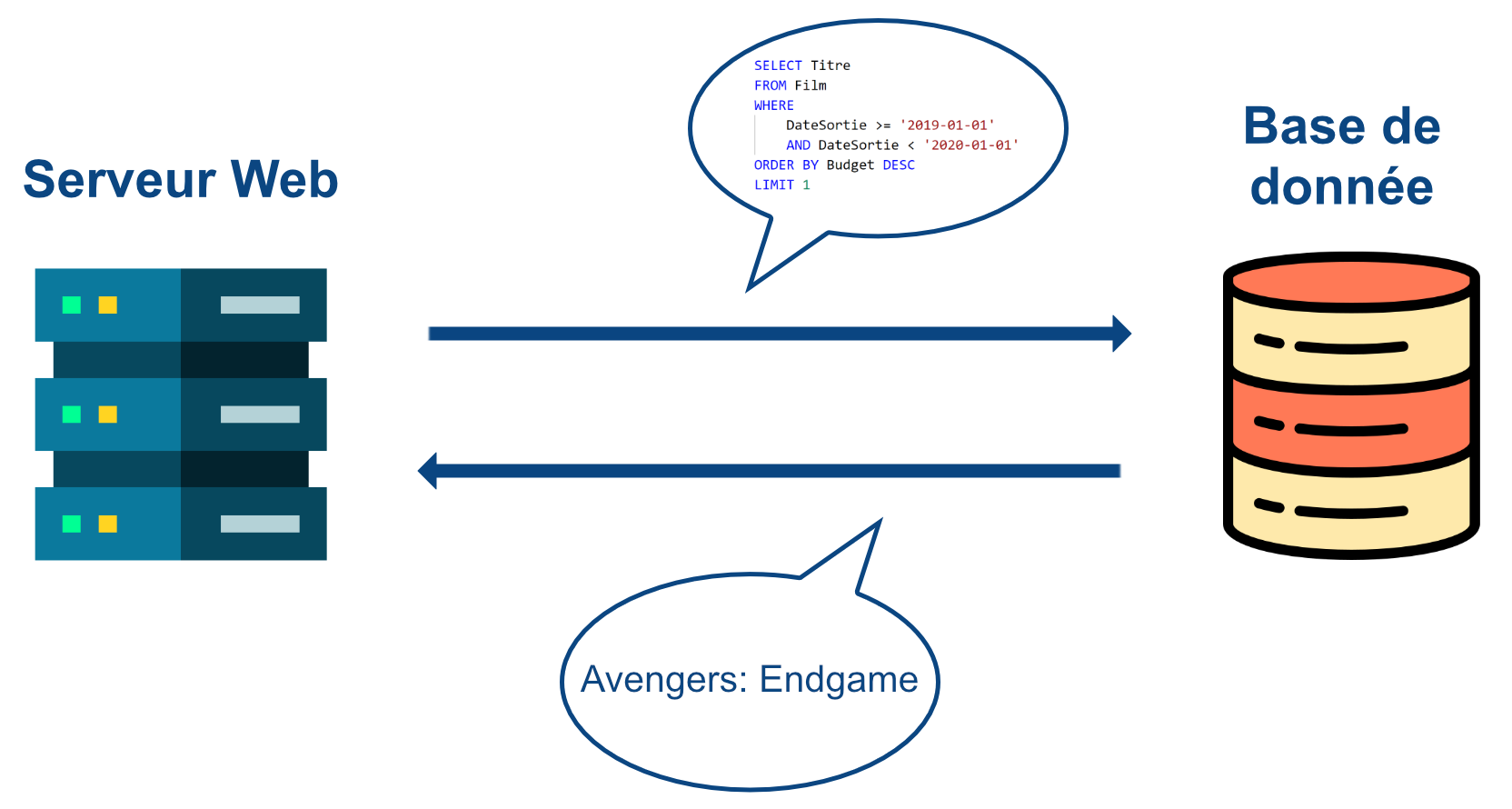
Base de données
Parfois, une page web aura besoin de récupérer des données externes, qui ne viennent ni du client, ni du serveur web, mais d’une base de données : un centre de stockage contenant plein de données destinées à être utilisées par des outils, dont le serveur web.
Similaire à HTTP, le serveur web va envoyer une requête à la base de données, et celle-ci va lui répondre avec les données qu’il a demandé.
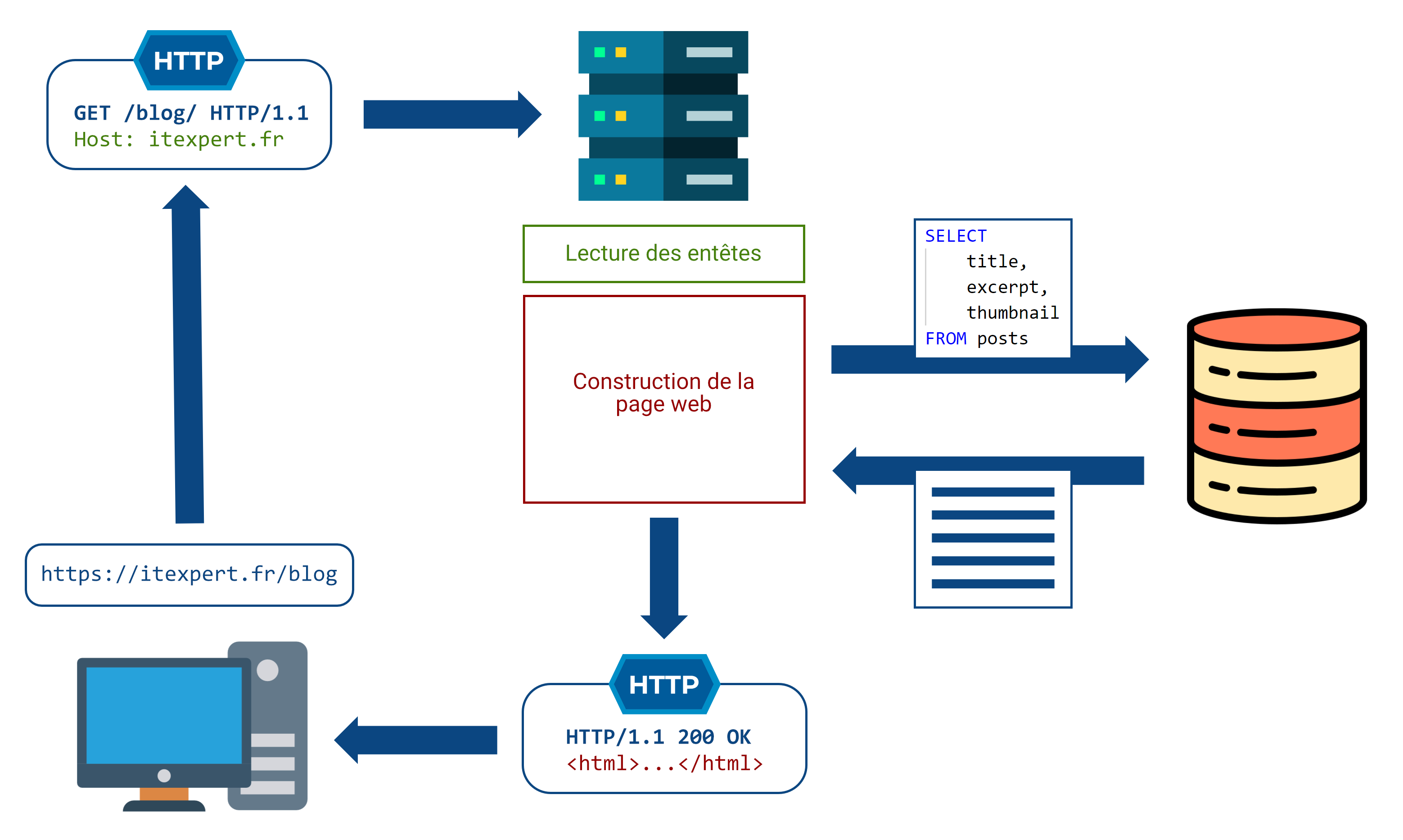
La grande image
Pour résumer, voilà ce qu’il se passe lorsque vous accédez au blog ITExpert (en version simplifiée). Vous pouvez télécharger l’image en Full HD 4K 144 FPS ici.
Et si vous avez d’autres interrogations, n’hésitez pas à poser un petit commentaire juste en dessous 😉
Afin d'éviter les spams, messages haineux ou insultants envers les autres commentateurs, tous les commentaires sont soumis à modération.